Mata Kuliah: Machine Learning
Tree-Based Algorithms
Decision Tree
Decision tree membagi dataset menjadi beberapa wilayah (berbentuk kotak). Algoritma ini memilih fitur dan ambang batas yang dapat membagi target dengan baik. Langkah ini diulangi hingga kedalaman maksimum yang diinginkan tercapai, yang akan membuat batasan untuk mengklasifikasikan data berdasarkan wilayah yang telah dibuat sebelumnya.
Sumber: medium.com/@axelivandatanjung
Decision Tree untuk Regresi
Algoritma decision tree mirip dengan regresi piecewise-linear. Decision tree membagi ruang input menjadi beberapa wilayah, dan menghitung nilai rata-rata target pada set

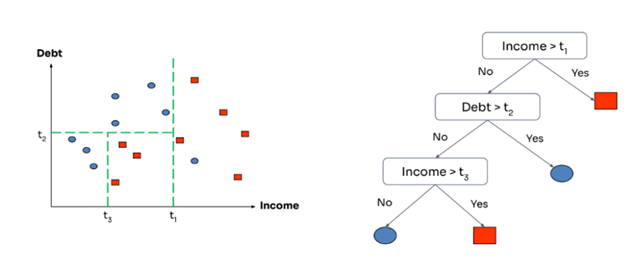
Komponen Decision Tree
Decision tree terdiri dari beberapa komponen utama:
- Decision tree seperti pohon, namun terbalik. Root ada di atas.
- Decision/internal node: uji nilai dari salah satu atribut/fitur input.
- Kumpulan edges/branches dari node: label dengan nilai atribut/fitur yang mungkin.
- Leaf node: output value.

Sumber: Pacmann Academy
Cara Split Node (Partisi)
- Cari batas partisi/sekat terbaik untuk masing-masing variabel prediktor.
- Bandingkan partisi terbaik dari semua variabel prediktor… pilih yang paling baik.
- Lakukan penyekatan/spliting berdasarkan variabel yang dihasilkan pada langkah ke-2.
- Lakukan langkah 1-2-3 untuk setiap node, sampai tercapai kriteria penghentian algoritma.
Contoh, asumsikan kita memiliki variabel income untuk memprediksi debt.

Sumber: Pacmann Academy
Cara Split Node (Partisi)
Hitung mean squared error (MSE) untuk setiap partisi (feature space) pada variabel income. Pilih partisi dengan nilai MSE terendah.

Sumber: Pacmann Academy
Aturan Penghentian
- Kedalaman Maksimum: Pohon berhenti tumbuh ketika kedalaman maksimum tercapai.
- Jumlah Sampel Minimum: Pohon berhenti tumbuh ketika jumlah sampel minimum di node daun tercapai.

Overfitting

Sumber: Pacmann Academy
Breiman, L. 2001. Random Forests. Machine Learning 45: 5–32.

Banyaknya Artikel Ilmiah di Google Scholar dengan kata pencarian “random forest breiman”

Algoritme Random Forest

Sumber: Wang et al. (2019)
Algoritme Random Forest
Ide Dasar:
- Ensemble dari ratusan/ribuan pohon
- korelasi prediksi antar pohon diusahakan minimal → diversity
Algoritme:
