Mata Kuliah: Machine Learning
Machine Learning Workflow
Background

Karakter data scientist (DS) baru:
- Bingung harus mulai dari mana.
- Penuh energi dan ingin menyelesaikan masalah menggunakan teknologi ML terbaru.
- Memiliki keterampilan di bidang matematika/statistika/ilmu komputer/bisnis.
- Tidak mengetahui end-to-end workflow ML.
Background

Kesalahan umum yang dilakukan oleh DS baru:
- Tidak memahami proses bisnis.
- Tidak tahu tipe model ML seperti apa yang harus dibangun.
- Hanya bisa bekerja jika datanya sudah bersih.
- Tidak tahu cara membersihkan data.
- Mendapatkan akurasi 99% pada data uji.
- Membuat model ML tetapi hanya melakukan fitting, tanpa pernah melakukan prediksi.
Common Machine Learning Workflow

Business Understanding
- Penting untuk memahami proses data tercipta, perjalanan pengguna (user journey), dan proses bisnis (business process).
- Anda dapat membangun solusi ML untuk mengotomatisasi proses bisnis.
Old Way

Business Understanding
- Penting untuk memahami proses data tercipta, perjalanan pengguna (user journey), dan proses bisnis (business process).
- Anda dapat membangun solusi ML untuk mengotomatisasi proses bisnis.
New Way

Objective Metrics
- Metrik objektif adalah ukuran yang digunakan untuk mengevaluasi model ML. Metrik ini biasanya berhubungan dengan metrik bisnis yang diterjemahkan.
Kasus leads scoring

Objective Metrics
- Metrik objektif adalah ukuran yang digunakan untuk mengevaluasi model ML. Metrik ini biasanya berhubungan dengan metrik bisnis yang diterjemahkan.
Kasus leads scoring

Objective Metrics
- Metrik objektif adalah ukuran yang digunakan untuk mengevaluasi model ML. Metrik ini biasanya berhubungan dengan metrik bisnis yang diterjemahkan.
- Selalu skeptis: Tidak langsung percaya pada hasil atau model Machine Learning (ML) tanpa melakukan verifikasi yang mendalam.
Kasus leads scoring

Data Preparation
- Data preparation adalah proses paling penting dalam ML.
- Tahapan umum dalam data preparation yaitu data gathering, data definition, dan data validation.
- Seorang DS harus mengerti konteks data yang digunakan dan tipe data sesuai dengan definisinya.

Data Splitting
Mana yang lebih bagus?

Data Splitting
Mana yang lebih bagus?
- Model B lebih bagus karena dapat memprediksi data yang belum pernah dilihat sebelumnya.

Data Splitting
Membagi (split) data menjadi 3 bagian:

Hati-hati dengan data leakage
- Data leakage adalah kondisi dimana data yang digunakan untuk training model juga digunakan untuk testing model.
- Bisa juga data target yang digunakan masuk juga ke dalam input data.
- Data leakage bisa membuat model ML menjadi overfitting, membuat seakan model ML sangat bagus tapi saat testing atau deployment performanya sangat buruk.

Hati-hati dengan data leakage
- Data leakage adalah kondisi dimana data yang digunakan untuk training model juga digunakan untuk testing model.
- Bisa juga data target yang digunakan masuk juga ke dalam input data.
- Data leakage bisa membuat model ML menjadi overfitting, membuat seakan model ML sangat bagus tapi saat testing atau deployment performanya sangat buruk.

Data Understanding (EDA)
Tujuan:
- Mencari pattern dalam data.
- Cari anomali yang mengurangi akurasi model.
- Tahap ini biasa disebut exploratory data analysis (EDA).


Feature Engineering
Feature engineering adalah proses membuat fitur baru (input baru) dari fitur yang sudah ada. Tujuannya adalah untuk meningkatkan performa model ML. Fitur baru ini lebih representatif dan informatif terhadap data target.

Fitting Model
Fitting model adalah proses dimana model ML belajar dari data training. Model ML akan mencari pola atau pattern dalam data training.
Hasil dari fitting dapat:
- Underfitting: Bias akan besar, tidak fit dengan data.
- Overfitting: Model terlalu kompleks, sensitif terhadap perubahan data.
- Good fit: Model memiliki performa yang baik.

Fitting Model
Trade-off antara bias dan variance:

Cross Validation
Cari hyperparameter terbaik dengan cross validation.
- Dari data training, kita bagi menjadi beberapa bagian (k-fold).
- Setiap bagian akan dijadikan data validasi, dan bagian lainnya sebagai data training.

Cross Validation
Cari hyperparameter terbaik dengan cross validation.

Evaluation
Lakukan evaluasi pada data uji (test).
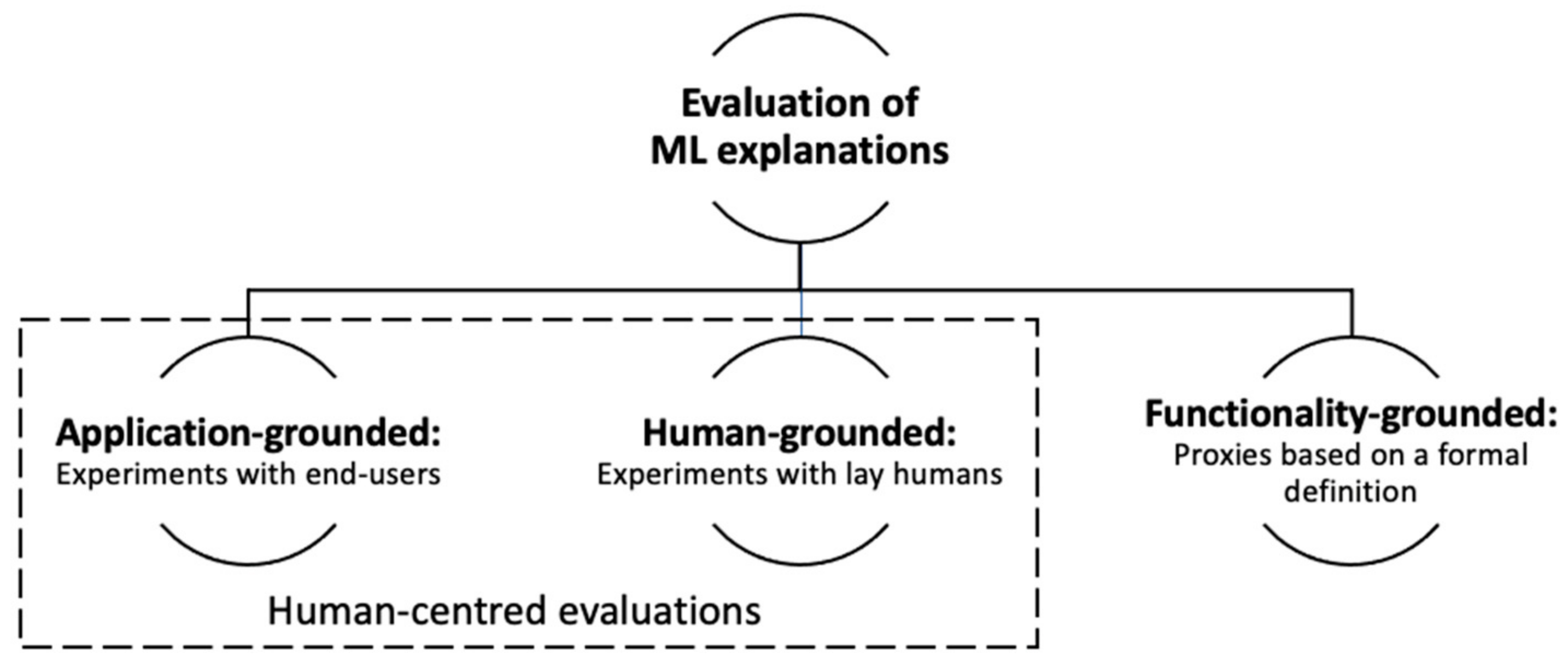
Evaluation
Lakukan evaluasi pada data uji (test).

Error Analysis
- Tujuan utama adalah mengetahui penyebab kesalahan pada model.
- Dengan memahami sumber kesalahan, performa model dapat ditingkatkan.
- Proses ini dilakukan dengan menganalisis error pada test set dan memahami alasan di balik kesalahan tersebut.
